
Import numpy as npy
Readme
Python复习:https://docs.python.org/zh-cn/3/tutorial/
NumPy用户指南:https://www.numpy.org.cn/
NumPy参考手册:https://www.numpy.org.cn/reference/
.
NumPy介绍
NumPy包的核心是 ndarray 对象,它封装了python原生的同数据类型的 n 维数组。
NumPy数组与原生的Python Array数组之间的区别:
NumPy数组数组大小固定,且数组内元素大小一致,执行相关操作效率更高。
NumPy大部分功能的基础:矢量化和广播
当涉及到ndarray时,逐个元素的操作是“默认模式”,但逐个元素的操作由预编译的C代码快速执行。
即使用NumPy,我们兼顾了python的简便写法和C/C++的快速
- 矢量化:代码中没有任何显式的循环、索引等
- 广播(Broadcasting):用于描述操作的隐式逐元素行为的术语,较小的数组可以在较大的数组上广播
.
快速入门教程
基础知识
- ndarray.ndim - 数组的轴(维度)的个数。在Python世界中,维度的数量被称为rank(即ndim的值为矩阵的秩)。
- ndarray.shape - 数组的维度。这是一个整数的元组,表示每个维度中数组的大小。对于有 n 行和 m 列的矩阵,
shape将是(n,m)。因此,shape元组的长度就是rank或维度的个数ndim。 - ndarray.size - 数组元素的总数。这等于
shape的元素的乘积。 - ndarray.dtype - 一个描述数组中元素类型的对象。可以使用标准的Python类型创建或指定dtype。另外NumPy提供它自己的类型。例如numpy.int32、numpy.int16和numpy.float64。
- ndarray.itemsize - 数组中每个元素的字节大小。例如,元素为
float64类型的数组的itemsize为8(=64/8),而complex32类型的数组的itemsize为4(=32/8)。它等于ndarray.dtype.itemsize。 - ndarray.data - 该缓冲区包含数组的实际元素。通常,我们不需要使用此属性,因为我们将使用索引访问数组中的元素。
.
数组创建
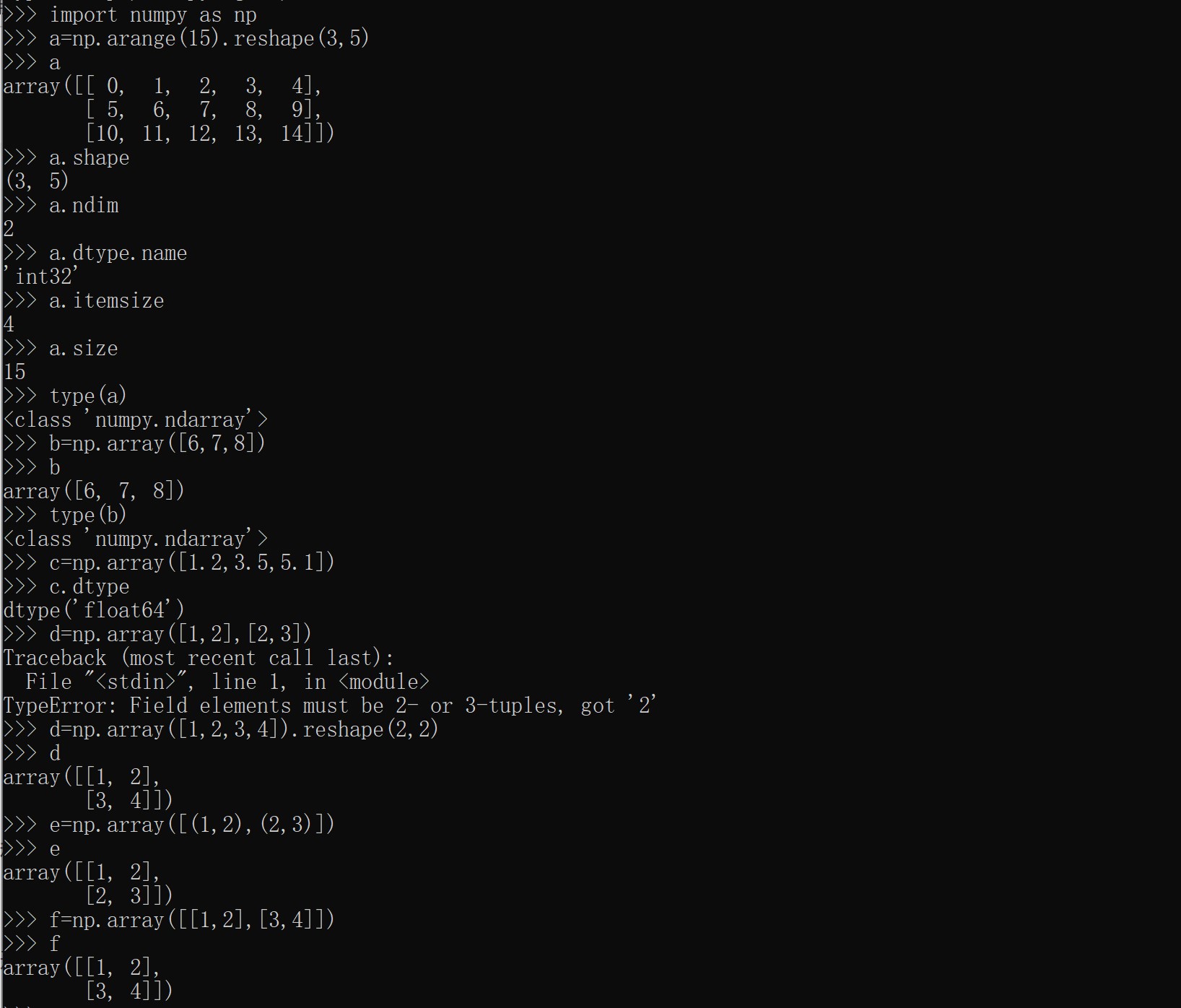
注意:创建多维数组,不能用a=np.array([1,2],[1,2]),而应该加[]或(),如a=np.array(([1,2],[1,2]))或a=np.array([[1,2],[1,2]])
除此之外,还有:
- zero:创建一个由0组成的数组,如
np.zeros((3,4)) - ones:创建一个由1组成的数组,如
np.ones((2,3,4))(三维) - empty:创建一个初始内容随机的数组,如
np.empty((2,3)) - range:创建一个等差增加的数组,如
np.arange(10,30,5)或np.arange(0,2,0.3)- 与浮点数一起使用时可使用
linspace函数来接收想要的元素数量的函数而不是步长(step)
- 与浮点数一起使用时可使用
打印数组时,会将一维数组打印成行,二维数组打印成矩阵,三维数组打印成矩数组表
如果数组太大而无法打印,NumPy会自动跳过数组的中心部分并仅打印角点,要禁用此行为并强制NumPy打印整个数组,可以使用更改打印选项set_printoptions
.
基本操作
数组上的算术运算符会应用到元素级别。
乘积运算符*在NumPy数组中按元素进行运算。矩阵乘积可以使用@运算符(在python> = 3.5中)或dot函数或方法执行。
某些操作(例如+=和 *=)会更直接更改被操作的矩阵数组而不会创建新矩阵数组。
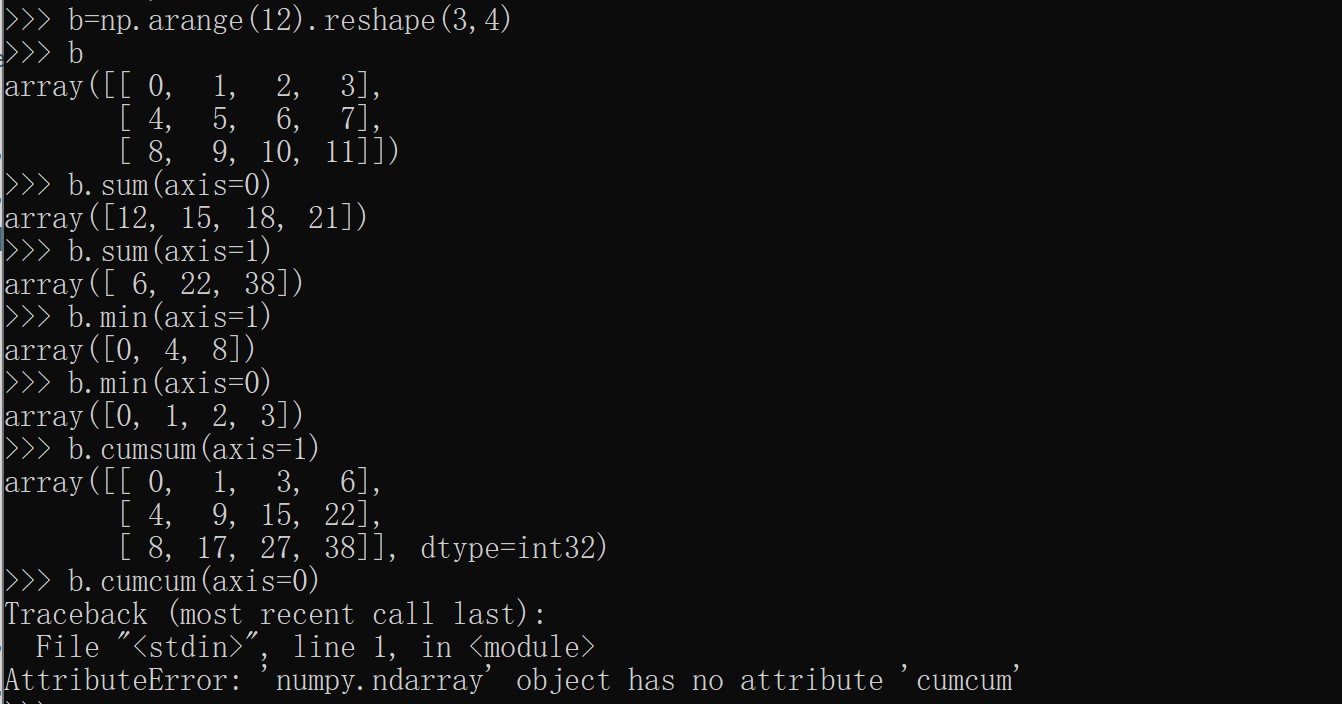
许多一元操作,例如计算数组中所有元素的总和,都是作为ndarray类的方法实现的:
1 | a=np.random.((2,3)) |
可以通过指定axis参数沿数组的指定轴应用操作:
.
通函数
在NumPy中,一些熟悉的数学函数被称为通函数(ufunc),这些函数在数组上按元素进行运算,产生一个数组作为输出。
常用的通函数:

.
索引、切片和迭代
一维数组同Python操作
多维数组每个轴可以有一个索引(层层索引)。当提供的索引少于轴的数量时,缺失的索引被认为是完整的切片:
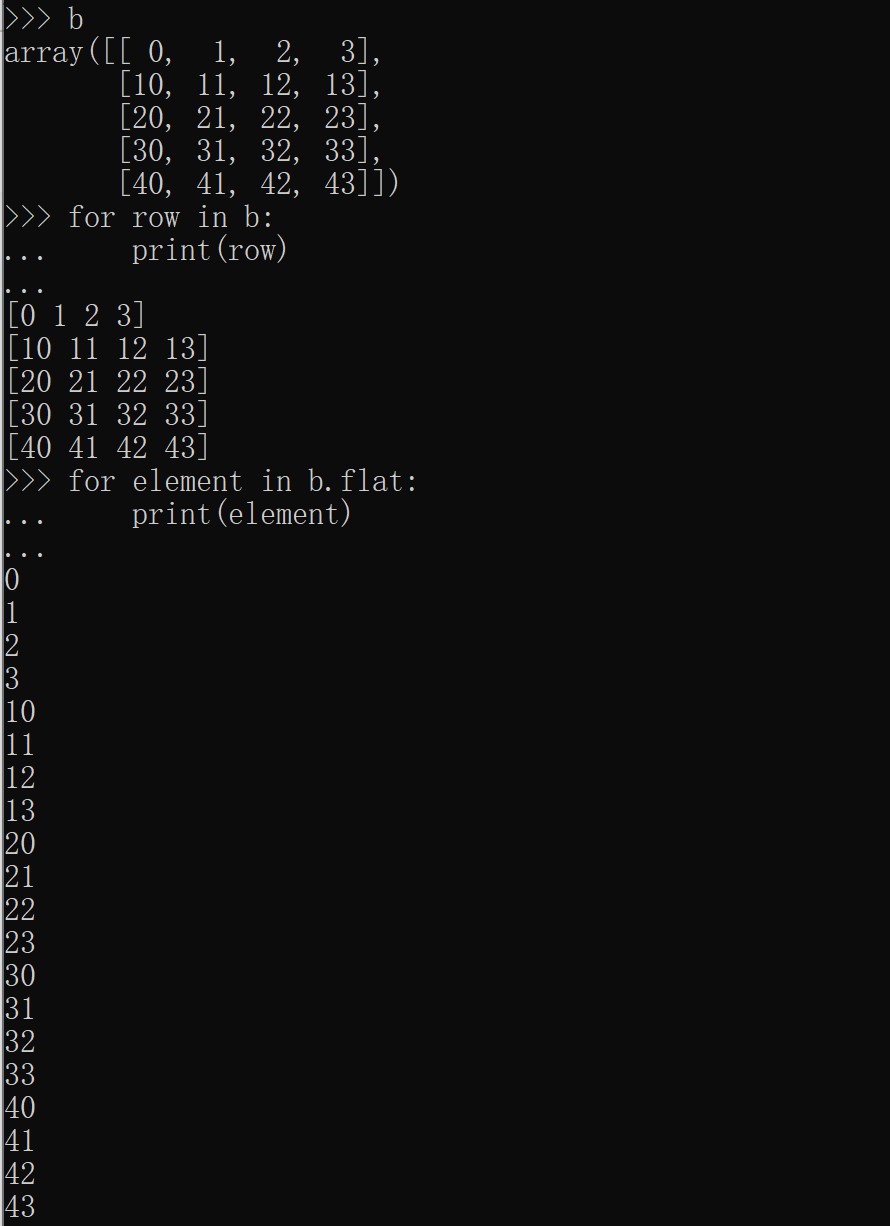
b[i] 方括号中的表达式 i 被视为后面紧跟着 : 的多个实例,用于表示剩余轴。NumPy也允许你使用三个点写为 b[i,...],三个点( ... )表示产生完整索引元组所需的冒号。
对多维数组进行迭代是相对于第一个轴完成的。如果想要对数组中的每个元素执行操作,可以使用flat属性:
.
形状操纵
一个数组的形状是由每个轴的元素数量决定的。
改变数组的形状
可以用各种命令更改数组的形状,以下三个命令都返回一个修改后的数组,但不会改变原始数组:
a.ravel()#将数组降成一维a.reshape(6,2)a.T#转置
注:a.resize((2,6))会改变原数组的形状
如果在 reshape 操作中将 size 指定为-1,则会自动计算其他的 size 大小,如a.reshape(3,-1)
.
将不同数组堆叠在一起
几个数组可以沿不同的轴堆叠在一起。
常用函数:
np.vstack((a,b)),np.hstack((a,b)),np.column_stack((a,b)),np.row_stack((a,b))。
.
将一个数组拆分成几个较小的数组
使用函数hsplit,可以沿数组的水平轴拆分数组,如:
np.hsplit(a,3):Split a into 3
np.hsplit(a,(3,4)):Split a after the third and the fourth column
.
拷贝和视图
完全不复制:直接赋值不会复制数组对象或其数据,如
b=a,a和b是同一数组对象的不同名称视图或浅拷贝:用view方法创建一个查看相同数据的新数组对象,与原数组对象共享相同的数据(即改变其中一个数据,另一个数据也随之改变)。如
c=a.view()。>>>c=a.view() >>>c is a False >>>c.base is a True1
2
3
4
5
6
7
8
9
* 深拷贝:用copy方法生成数组及其数据的完整副本(即**与原数组对象及其数据完全无关**)
* ```python
>>>d=a.copy()
>>>d is a
False
>>>d.base is a
False有时,如果不再需要原始数组,则应在切片后调用
copy。例如,假设a是一个巨大的中间结果,最终结果b只包含a的一小部分,那么在用切片构造b时应该做一个深拷贝:1
2
3a = np.arange(int(1e8))
b = a[:100].copy()
del a # the memory of ``a`` can be released.
.
Less基础
广播允许通用功能以有意义的方式处理不具有完全相同形状的输入。
广播规则:
- 如果所有输入数组不具有相同数量的维度,则将“1”重复地预先添加到较小数组的形状,直到所有数组具有相同数量的维度。
- 确保沿特定维度的大小为1的数组表现为具有沿该维度具有最大形状的数组的大小。假定数组元素的值沿着“广播”数组的那个维度是相同的。
.
花式索引和索引技巧
NumPy的索引功能比Python更多:整数、切片、索引数组和布尔数组。
详细见用户指南。
**ix_()**函数:
用于组合不同的向量,以便获得每个n-uplet的结果
使用字符串建立索引:详见“结构体数组”
.
线性代数
a=np.array([[1.0,2.0],[3.0,4.0]])
- a.transpose():转置
- np.linalg.inv(a):矩阵求逆
- u=np.eye(2):创建单位阵
- a@a:矩阵的乘积
- np.trace(a):求迹
- np.linalg.solve(a):求解多元一次方程
- np.linalg.eig(a):求特征向量
更多可参阅numpy文件夹中的linalg.py
.
技巧和提示
自动整形:
a.shape=2,-1,3,-1 means whatever is needed矢量堆叠:如将同等大小的行向量列表构成数组
直方图
.




