
NLP前沿论文
ReadMe
本文对标任务0:
阅读1.3中四星以上的论文(遇到不懂之处可搜索相关中英文博客辅助理解),撰写报告说明Transformer的基本结构,并对比BERT、GPT、T5、BART这几类预训练模型的异同(模型结构、预训练方式、主要应用等)
一、Transformer
类型:基础模型
主题:Transformer
Recurrent neural networks:递归神经网络(RNN)
Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output.
Transformer是一种避开递归网络的模型体系结构,并且完全依赖于注意力机制来绘制输入和输出之间的全局依存关系。
Transformer对编码器和解码器使用堆叠式的自注意力和逐点,全连接层。
个人理解,Attention机制的本质就是加权求和。
transformer基本结构
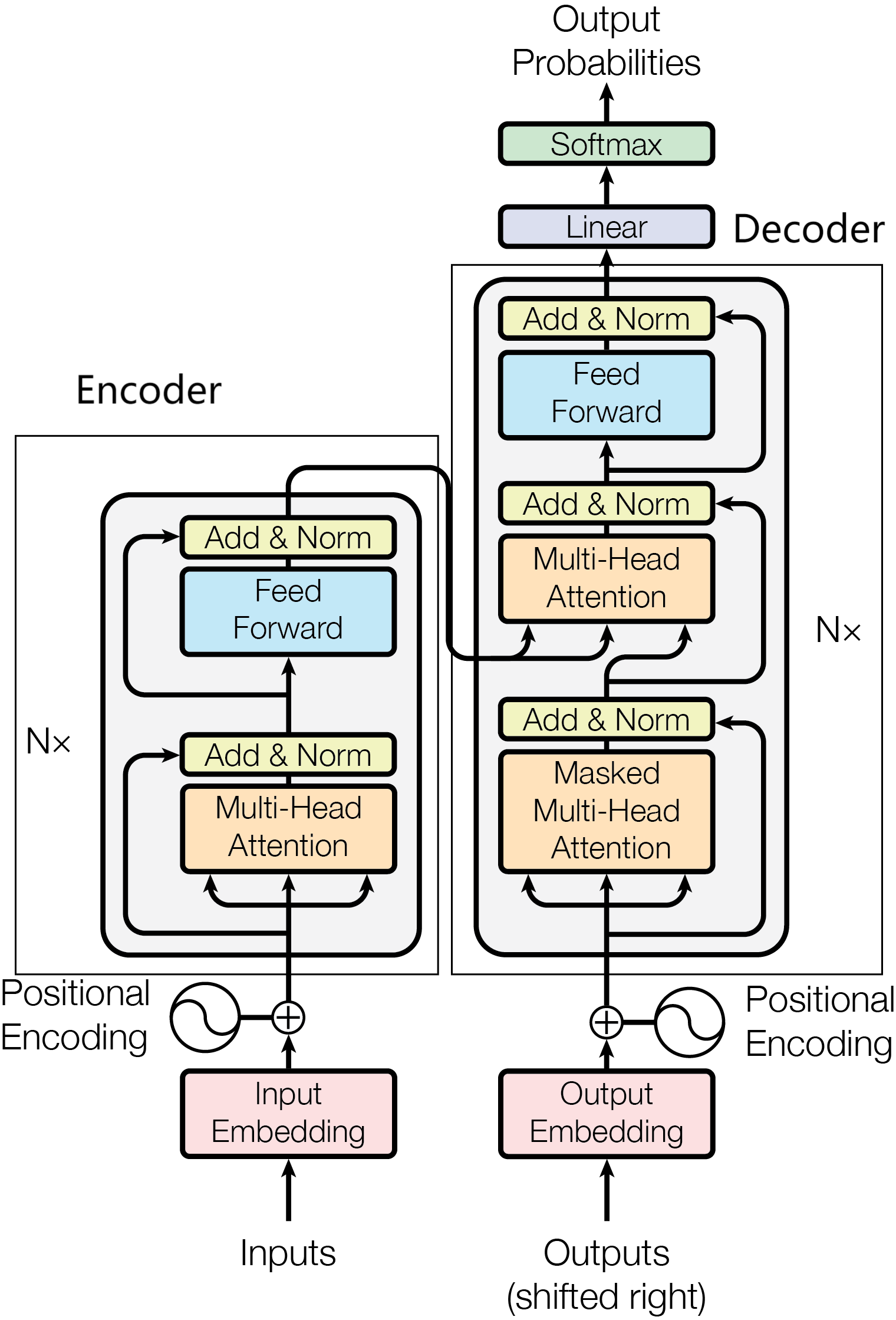

Transformer遵循Encoder-Decoder结构,见图1。
Encoder具有两层结构,self-attention和前馈神经网络。self-attention计算句子中每个词和其他词的关联,从而帮助模型更好地理解上下文语义,引入Multi-Head Attention后,每个头关注句子中的不同位置,增强了句子内部单词之间作用的表达能力;前馈神经网络为encoder引入非线性变换,增强了模型的拟合能力。
Decoder接受output输入的同时还接受encoder的输入,帮助当前节点获取到需要重点关注的内容。
Multi-Head Attention
Attention是将query和key映射到同一高维空间中去计算相似度,而Multi-Head Attention则是将query和key映射到高维空间α的不同子空间$(\alpha_1,\alpha_2,…,\alpha_h)$中去计算相似度。
$$
Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V [1]
$$
$$
MultiHead(Q,K,V)=Concat(head_1,…,head_h)W^O
$$
$$
where head_i=Attention(QW_i^Q,KW_i^K,VW_i^V) [2]
$$
论文采用点乘注意力(dot-product attention),将多个query堆叠成Q,同理keys和values也被堆叠成K和V,通过上述公式1来计算矩阵输出。论文对queries,keys和values做h次不同的投影,将结果拼接在一起,最后通过一个线性映射输出,通过Multi-Head Attention,模型可以获得不同子空间下的位置信息,如图3。
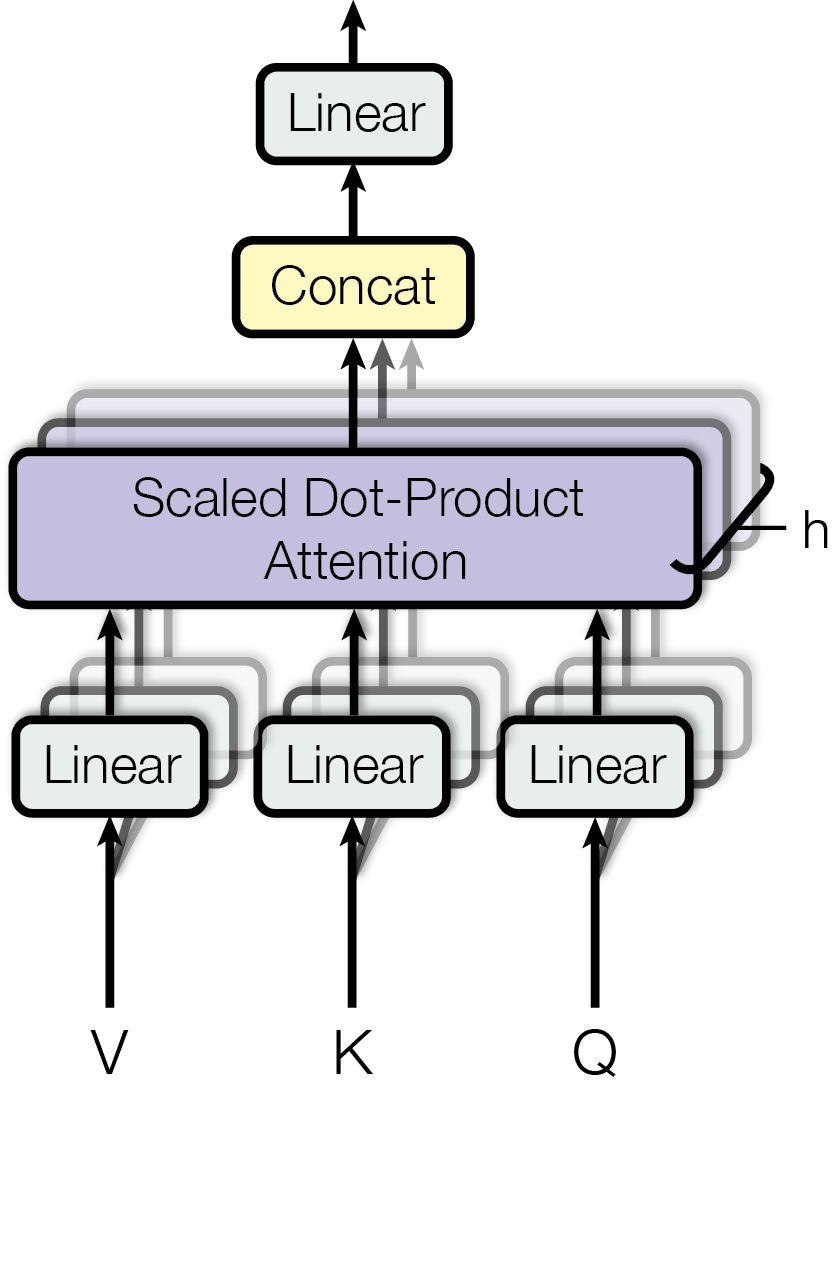
Transformer会在三个不同的方面使用multi-headattention:
1.encoder-decoder attention:使用multi-head attention,输入为encoder的输出和decoder的self-attention输出,其中encoder的self-attention作为 key and value,decoder的self-attention作为query
2.encoder self-attention:使用 multi-head attention,输入的Q、K、V都是一样的(input embedding and positional embedding)
3.decoder self-attention:在decoder的self-attention层中,deocder 都能够访问当前位置前面的位置
Position-wise Feed Forward
FFN包含两个线性变化和ReLU激活函数:
$$
FFN(x)=max(0,xW_1+b_1)W_2+b_2
$$
可以看成是两层的1*1的1d-convolution,hidden-size变化为:512->2048->512
Layer Normalization
随着网络层数的增加,数据分布不断发生变化,偏差越来越大,导致不得不使用更小的学习率来稳定梯度。Layer Normalization 的作用就是保证数据特征分布的稳定性,将数据标准化到ReLU激活函数的作用区域,可以使得激活函数更好的发挥作用
Positional Encoding
由于模型中没有循环和卷积结构,为了使用序列的顺序,我们需要将位置信息记录,论文里采用如下方式:
$$
PE_{(pos,2i)}=sin(pos/10000^{2i/d_{model}})
$$
$$
PE_{(pos,2i+1)}=cos(pos/10000^{2i/d_{model}})
$$
因为正余弦函数具有周期性,对于固定长度偏差k(类似于周期),pos +k位置的PE可以表示成关于pos位置PE的一个线性变化(存在线性关系),这样可以方便模型学习词与词之间的一个相对位置关系。
Residual Network
在transformer模型中,encoder和decoder各有6层,为了使当模型中的层数较深时仍然能得到较好的训练效果,模型中引入了残差网络。
Linear and Softmax
Decoder最后是一个线性变换和softmax层。线性变换层是一个简单的全连接神经网络,它可以 把解码组件产生的向量投射到一个比它大得多的、被称作对数几率(logits)的向量里 。而Softmax层会把分数变成概率,概率最高的单元格被选中,并且它对应的单词被作为这个时间步的输出。
参考资料:
https://zhuanlan.zhihu.com/p/36699992
https://blog.51cto.com/u_14300986/5467365
https://blog.csdn.net/Lamours/article/details/125192046
.
二、BERT
论文:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
类型:预训练模型(Encoder)
主题:BERT
BERT使得我们可以构建一个深的神经网络,应用在许多NLP的任务上面。
模型结构
BERT的全称为“Bidirectional Encoder Representations from Transformer”,也就是说Transformer是组成BERT的核心模块,BERT的模型结构是一个多层双向的Transformer编码器(BERT模型未用到解码器),而双向编码会同时考虑上下文的信息。
BERT的输入由三部分组成:
Input = token embeddings + segment embeddings + position embeddings(如图)
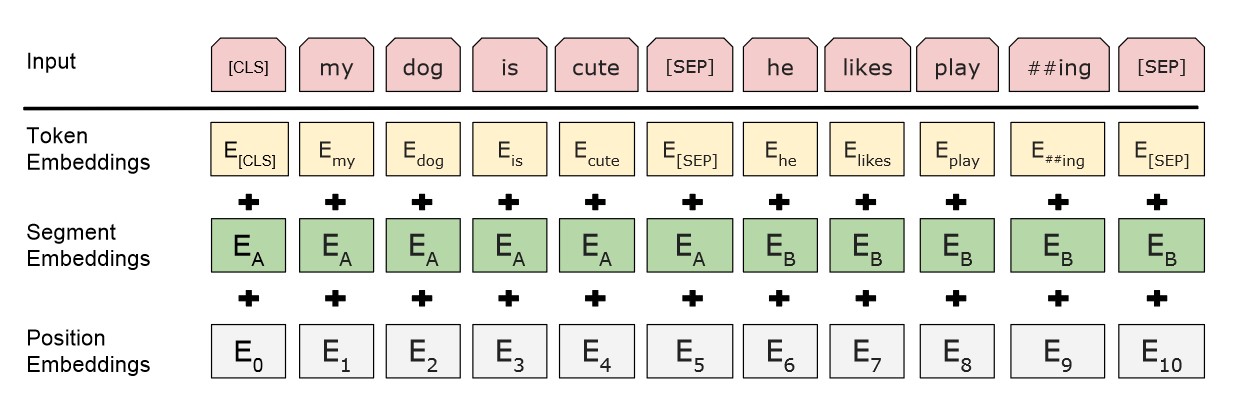
Token Embeddings:对Input中所有词汇做正常的embeddings,如随机初始化
Segment Embeddings:区分两个句子,第一个句子(包括[CLS]和[SEP])用0表示,后面的句子用1表示;若输入仅有一个句子,那么它的Segment Embeddings全为0
[CLS]I like dogs[SEP]I like cats[SEP] 对应编码 0 0 0 0 0 1 1 1 1
[SEP]I Iike dogs and cats[SEP] 对应编码 0 0 0 0 0 0 0
Position Embeddings:在transformer中此部分用正余弦函数表示,而此处使用随机初始化,让模型自己去学习出来。如第1个位置定为0,第2个位置定为1……
预训练方式
作者提出了两个预训练任务:Masked LM (MLM)和Next Sentence Prediction (NSP)
BERT模型通过对MLM任务和NSP任务进行联合训练,使模型输出的每个字/词的向量表示都尽可能全面准确地刻画输入文本的整体信息,为后续的微调任务提供更好的模型参数初始值。
MLM
MLM: mask some percentage of the input tokens at random, and then predict those masked token. 即给定一句话,随机抹去这句话中的一个或几个词,要求根据剩余词汇预测被抹去的几个词分别是什么(类似完形填空)。
预训练过程中,在一句话中随机选择15%的词汇用于预测,对于在原句中被抹去的词汇,80%情况下采用一个特殊符号[MASK]替换,10%情况下采用一个任意词替换,剩余10%情况下保持原词汇不变。
这样在预测一个词汇时,模型并不知道输入对应位置的词汇是否为正确的词汇(10%),这就迫使模型更多地依赖于上下文信息去预测词汇,赋予了模型一定的纠错能力。
NSP
NSP:to understand sentence relationships. 即给定一篇文章中的两句话,判断第二句话在文本中是否紧跟在第一句话之后。
预训练过程中,从文本语料库中随机选择50%正确语句对和50%错误语句对进行训练。
[SEP]符号:负责告诉模型前面是一个句子,后面又是一个句子
[CLS]符号:在句子最前面加上[CLS]符号,在训练的时候,将[CLS]的输出向量接一个二分类器,去做一个二分类任务。
主要应用
句对分类
给定两个句子,判断它们的关系,称为句对分类,例如判断句对是否相似、判断后者是否为前者的答案。
如下图所示,句对用 [SEP] 分隔符拼接成文本序列,在句首加入标签 [CLS],将句首标签所对应的输出值作为分类标签,计算预测分类标签与真实分类标签的交叉熵,将其作为优化目标,在任务数据上进行微调训练。
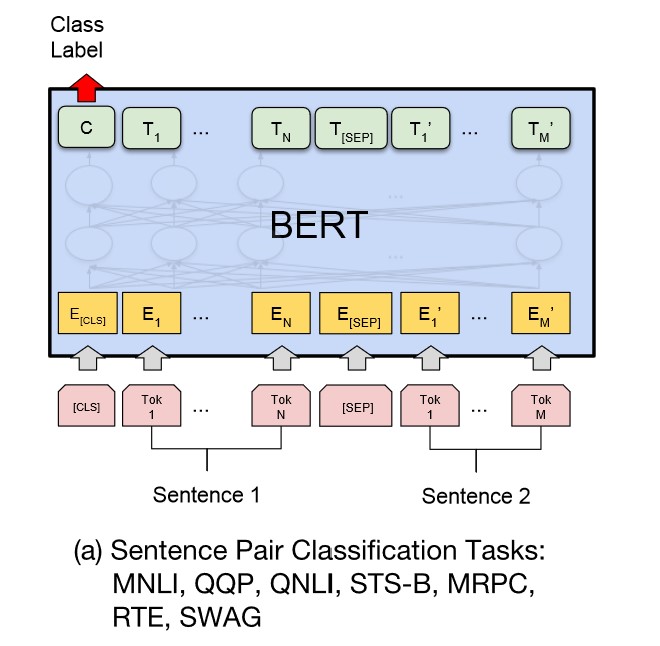
针对二分类任务,BERT 不需要对输入数据和输出数据的结构做任何改动,直接使用与 NSP 训练方法一样的输入和输出结构就行。
针对多分类任务,需要在句首标签 [CLS] 的输出特征向量后接一个全连接层和 Softmax 层,保证输出维数与类别数目一致,最后通过 arg max 操作(取最大值时对应的索引序号)得到相对应的类别结果。
单句分类
给定一个句子,判断该句子的类别,统称为单句分类,例如判断情感类别、判断是否为语义连贯的句子。
如下图所示,单句分类在句首加入标签 [CLS],将句首标签所对应的输出值作为分类标签,计算预测分类标签与真实分类标签的交叉熵,将其作为优化目标,在任务数据上进行微调训练。
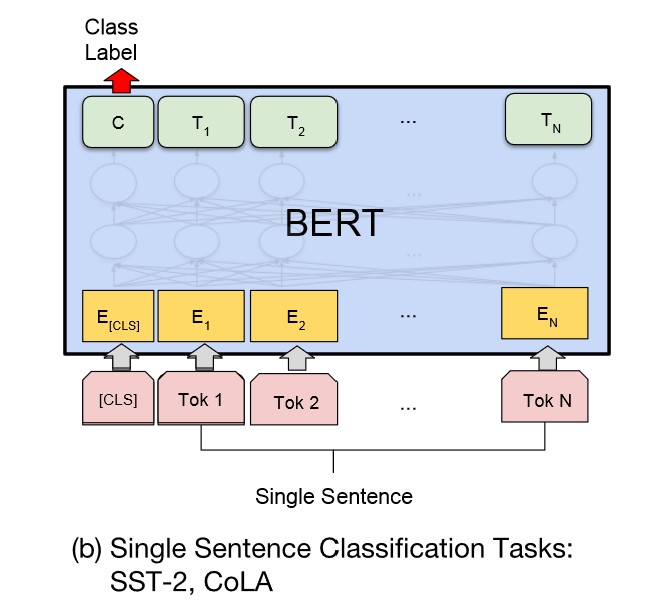
同样,针对多分类任务,需要在句首标签 [CLS] 的输出特征向量后接一个全连接层和 Softmax层,保证输出维数与类别数目一致,最后通过 argmax 操作得到相对应的类别结果。
文本问答
给定一个问句和一个蕴含答案的句子,找出答案在后这种的位置,称为文本问答,例如给定一个问题(句子 A),在给定的段落(句子 B)中标注答案的其实位置和终止位置。
为了标注答案的起始位置和终止位置,BERT 引入两个辅助向量 s(start,判断答案的起始位置) 和 e(end,判断答案的终止位置)。
如下图所示,BERT 判断句子 B 中答案位置的做法是,将句子 B 中的每一个词得到的最终特征向量 $T_{i’}$ 经过全连接层(利用全连接层将词的抽象语义特征转化为任务指向的特征)后,分别与向量 s 和 e 求内积,对所有内积分别进行 softmax 操作,即可得到词 Tok m((min [1,M]))作为答案其实位置和终止位置的概率。最后,取概率最大的片段作为最终的答案。
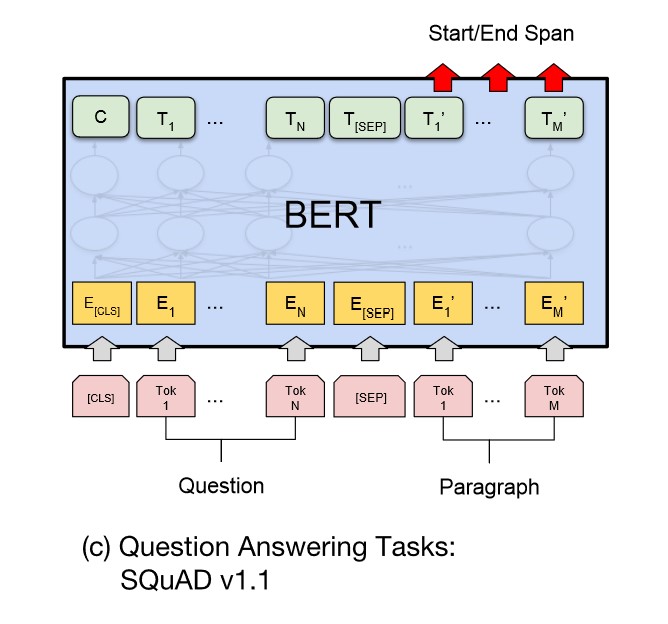
单句标注
给定一个句子,标注每个次的标签,称为单句标注。例如给定一个句子,标注句子中的人名、地名和机构名。
单句标注任务与文本问答任务较为相似。如下图所示,在进行单句标注任务时,需要在每个词的最终语义特征向量之后添加全连接层,将语义特征转化为序列标注任务所需的特征,单句标注任务需要对每个词都做标注,因此不需要引入辅助向量,直接对经过全连接层后的结果做 Softmax 操作,即可得到各类标签的概率分布。
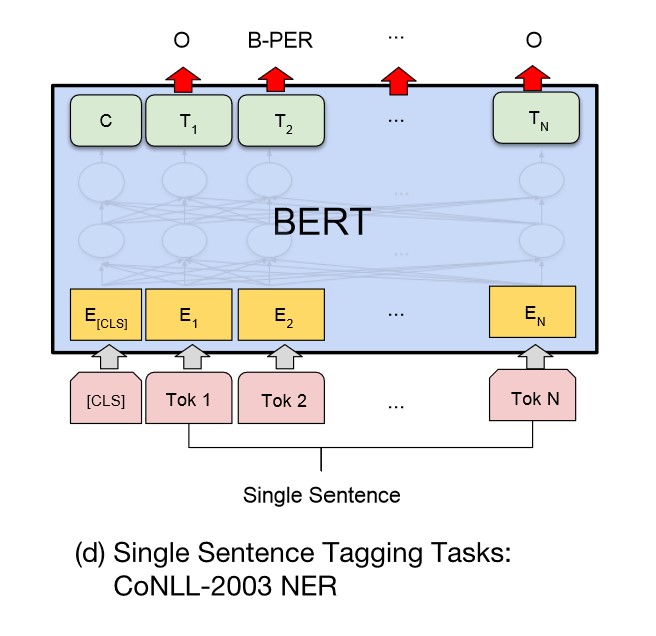
由于 BERT 需要对输入文本进行分词操作,独立词将会被分成若干子词,因此 BERT 预测的结果将会是 5 类(细分为 13 小类):
- O(非人名地名机构名,O 表示 Other)
- B-PER/LOC/ORG(人名/地名/机构名初始单词,B 表示 Begin)
- I-PER/LOC/ORG(人名/地名/机构名中间单词,I 表示 Intermediate)
- E-PER/LOC/ORG(人名/地名/机构名终止单词,E 表示 End)
- S-PER/LOC/ORG(人名/地名/机构名独立单词,S 表示 Single)
将 5 大类的首字母结合,可得 IOBES,这是序列标注最常用的标注方法。
.
参考资料:
.
三、GPT
论文:GPT1: Improving Language Understanding by Generative Pre-Training
GPT2:Language Models are Unsupervised Multitask Learners
GPT3:Language Models are Few-Shot Learners
类型:预训练模型(Decoder)
主题:GPT
GPT1
模型结构
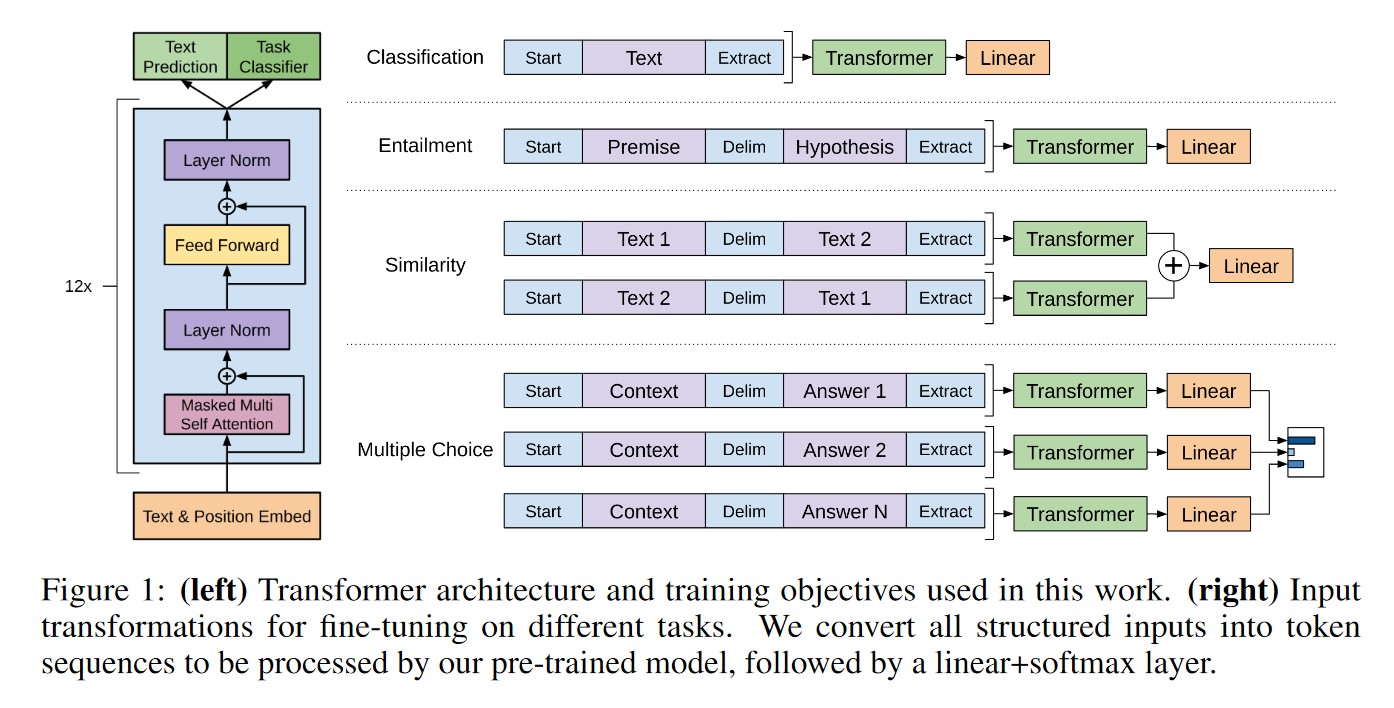
GPT1的结构:基于Transformer Decoder,由12个Transformer中的Decoder模块经修改后组成(Transformer本身由6个Encoder和6个Decoder组成)
- Transformer Decoder:Masked multi-head self-attention + multi-head self-attention +feed forward
- GPT Decoder:Masked multi-head self-attention+ feed forward
预训练方式
GPT1通过二段式训练,第一个阶段是利用语言模型进行预训练(无监督形式),第二阶段通过Fine-tuning的模式解决下游任务(监督模式下)。
Unsupervised pre-training
给定一个未标注的预料库$U={u_1,…,u_n}$,对参数进行最大(对数)似然估计:
$L_1(U)=\Sigma_ilogP(u_i|u_{i-k},…,u_{i-1};\theta)$
其中,k为上下文窗口大小,$\theta$ 为模型参数,其训练方式使用的是Adam优化器。
首先根据token embedding matrix $W_e$和position embedding matrix $W_p$来计算得到模型的输入:$h_0=U*W_e+W_p$
其次将输入传进Decoder模块:
$h_l=transformer_lock(h_{l-1}) , l∈[1,n]$
n为Decoder的层数。
最后,经过n次上述步骤以后,将最终输出的结果$h_n$传入softmax进行计算,得到对应的标签的概率分布。
Supervised fine-tuning
假设监督数据集合C的输入X是一个序列$x^1,x^2,…,x^m$,输出是一个分类y的标签。
把$x^1,x^2,…,x^m$输入 Transformer 模型,得到最上层最后一个时刻的输出$h_l^m$,将其通过我们新增的一个 Softmax 层(参数为$W_y$)进行分类,最后用交叉熵计算损失,从而根据标准数据调整 Transformer 的参数以及 Softmax 的参数 。这等价于最大似然估计:
$P(y|x^1,…,x^m) = softmax(h_l^mW_y)$
$W_y$表示预测输出时的参数,微调时候需要最大化以下函数:
$L_2(C)=\Sigma_{x,y}logP(y|x^1,…,x^m)$
正常来说,我们应该调整参数使得$L_2$最大,但是为了提高训练速度和模型的泛化能力,我们使用 Multi-Task Learning,GPT 在微调的时候也考虑预训练的损失函数
$L_3(C)=L_2(C)+\lambda×L_1(C)$
这里使用的$L_1$还是之前语言模型的损失(似然),但是使用的数据不是前面无监督的数据U,而是使用当前任务的数据C ,而且只使用其中的X ,而不需要标签y。
主要应用
问答或常识推理
蕴含
相似度
.
GPT2
模型结构
与第一代GPT模型相I比,GPT2在模型结构上改动极小、在复用GPT1的基础上,GPT2做了以下修改:
(1)LN层被放置在Self-Attention层和Feed Forward层前,而不是像原来那样后置。
(2)在最后一层Tansfomer Block后增加了LN层。
(3)修改初始化的残差层权重,缩放为原来的$\sqrt{N}$。其中,N是残差层的数量。
(4)特征向量维数从768扩展到1600,词表扩大到50257。
(5)Transformer Block的层数从12扩大到48。
预训练方式
GPT2彻底放弃微调阶段,仅通过大规模多领域的数据预训练,让模型在Zero-shot Learning的设置下自己学会解决多任务的问题。
.
GPT3
模型结构
使用了和 GPT2 相同的模型和架构,包括改进的初始设置、预归一化和 reversible tokenization。区别在于 GPT3 在 transformer 的各层上都使用了交替密集和局部带状稀疏的注意力模式,类似于 Sparse Transformer。
预训练方式
GPT-3 的训练过程与 GPT-2 类似,但对模型大小、数据集大小与多样性、训练长度都进行了相对直接的扩充。关于语境学习,GPT-3 同样使用了与 GPT-2 类似的方法,不过 GPT-3 研究团队系统地探索了不同的语境学习设定。
GPT3在Few-shot Learning设置下的性能十分优异,在自然语言处理下游任务性能评测中,GPT-2在Zero-shot Learning设置下的性能表现远不如SOTA模型,而GPT-3在Few-shot Learning设置下的性能表现与当时的SOTA模型持平,甚至超越了SOTA模型。
.
参考资料:
.
四、BART
类型:预训练模型(Denoise)
主题:BART
模型结构
BART吸收了BERT的bidirectional encoder和GPT的left-to-right decoder各自的特点
BART模型——用来预训练seq-to-seq模型的降噪自动编码器(autoencoder)
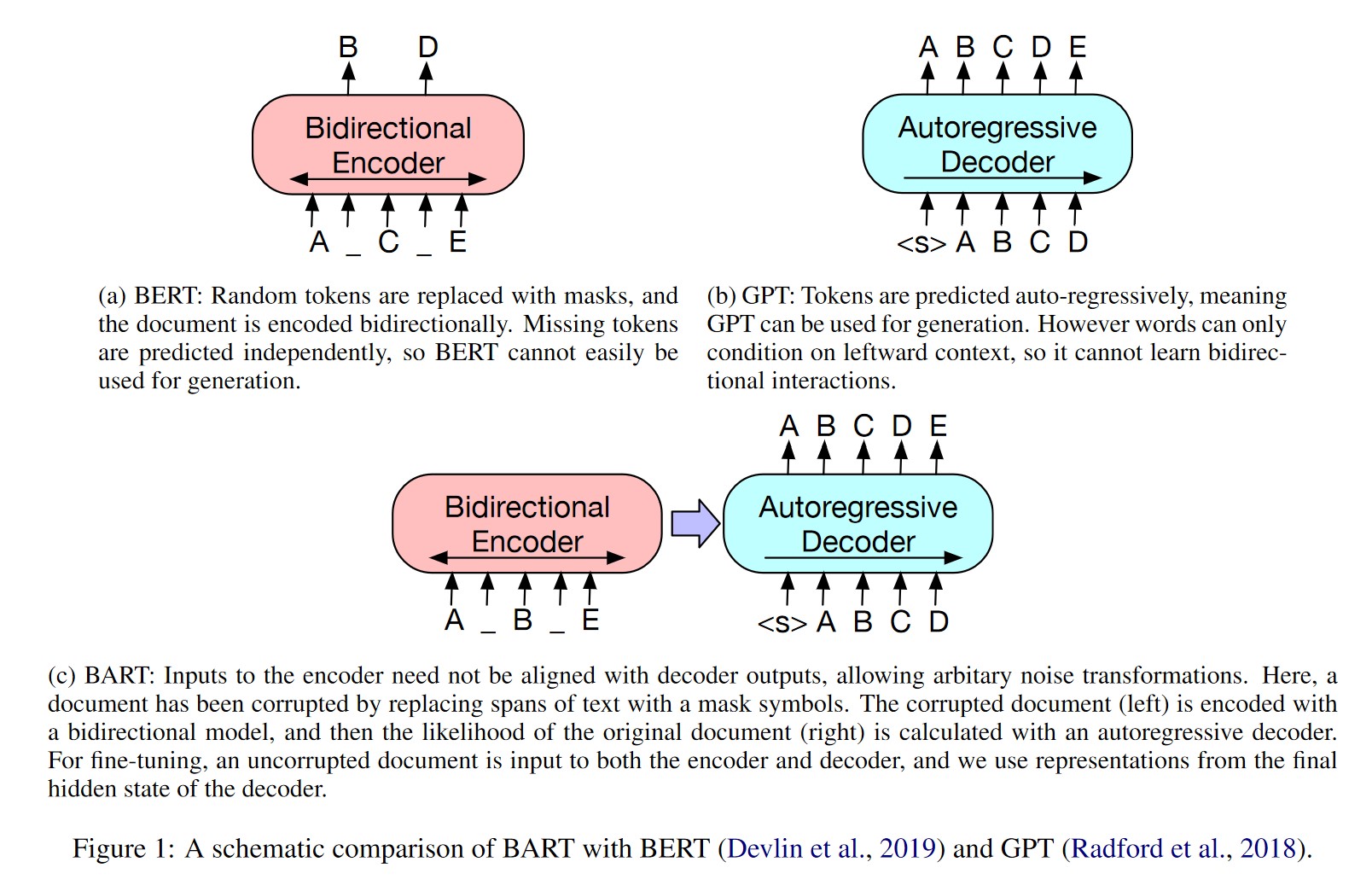
预训练方式
BART的训练包括两步:
1.利用任意一种噪声函数分解文本
2.学习一个模型来重构回原来的文本
相比BERT中单一的noise类型(只简单地用[MASK] token进行替换),BART在encoder端尝试了多种noise,如下:
Token Masking: 就是BERT的方法—-随机将token替换成[MASK];
Token Deletion: 随机字符将从输入中删除。与字符屏蔽相反,该模型必须确定哪些位置缺少输;
Text Infilling: 随机将一段连续的token(称作span)替换成一个[MASK],span的长度服从λ=3的泊松分布。注意span长度为0就相当于插入一个[MASK];
Sentence Permutation: 根据句号将文档分为多个句子,然后将这些句子随机排列;
Document Rotation: 从document序列中随机选择一个token,然后使得该token作为document的开头。
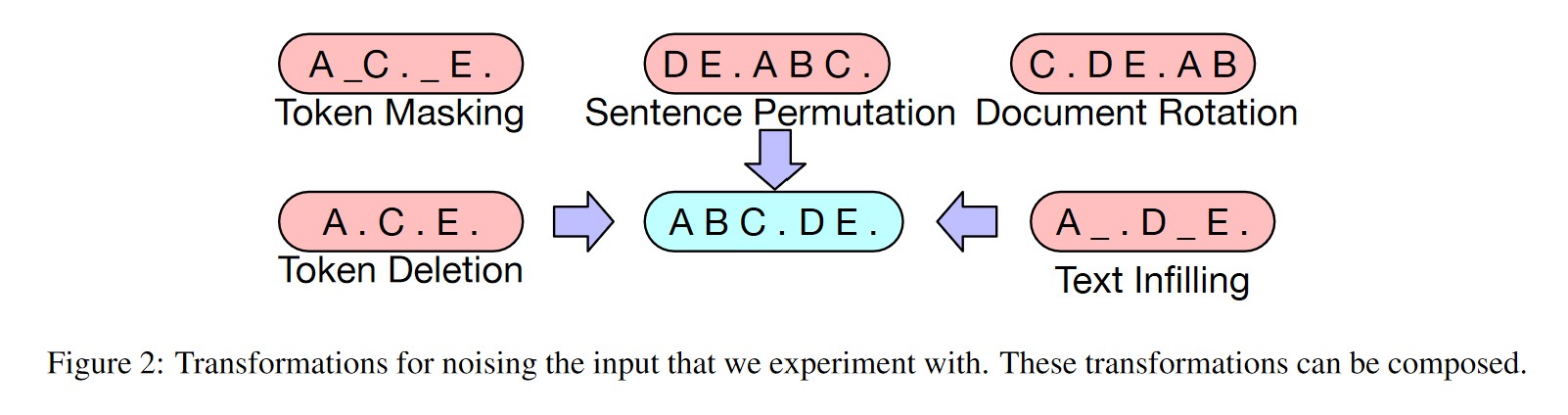
主要应用
- Sequence Classification Tasks
- Token Classification Tasks
- Sequence Generation Tasks
- Machine Translation
.
参考资料:
.
五、T5
论文:Exploring the limits of transfer learning with a unified text-to-text transformer
类型:预训练模型(Encoder-Decoder)
主题:T5
模型结构
T5:Text-to-Text Transfer Transformer
T5模型将NLP的各种任务都转化成Text-to-Text任务,从而使得这些任务在pre-training和fine-tuning时能够使用相同的目标函数,在测试时也能使用相同的解码过程。
T5模型和原始的Transfomer结构基本一致,除了以下改变:
- remove the Layer Norm bias
- place the Layer Normalization outside the residual path
- use a different position embedding(每个位置编码都是一个标量,被加到 logits上用于计算注意力权重。各层共享位置编码,但是在同一层内,不同的注意力头的位置编码都是独立学习的。一定数量的位置Embedding,每一个对应一个可能的key-query位置差。作者学习了32个Embedding,至多适用于长度为128的位置差,超过位置差的位置编码都使用相同的Embedding。)
预训练方式
T5在无监督和监督任务的多任务混合上进行预训练,其中每个任务都被转换为Text-to-Text格式
.
参考资料:
.




